


Explain the term training test and validation sets.
Choosing the right dataset for a given classification task is of crucial importance for the generalization performance. Ultimately, the model’s ability to classify unseen data correctly is highly dependent on the quality of the underlying dataset itself. For an image classification problem, the network’s input X consists of a variety of grayscale or color images and their corresponding ground truth labels y. An image X can be viewed as a c x h x w tensor of numbers with c color channels and corresponding height h and width w. For a color image, its three channels correspond to the red, green, and blue (RGB) intensities at each pixel. Conversely, for a grayscale image, its single channel corresponds to the grayscale intensity.
For any supervised machine learning task, it is common to split the entire dataset into three subsets called the training set, the test set, and the validation set. They each serve a different purpose and are motivated as follows-
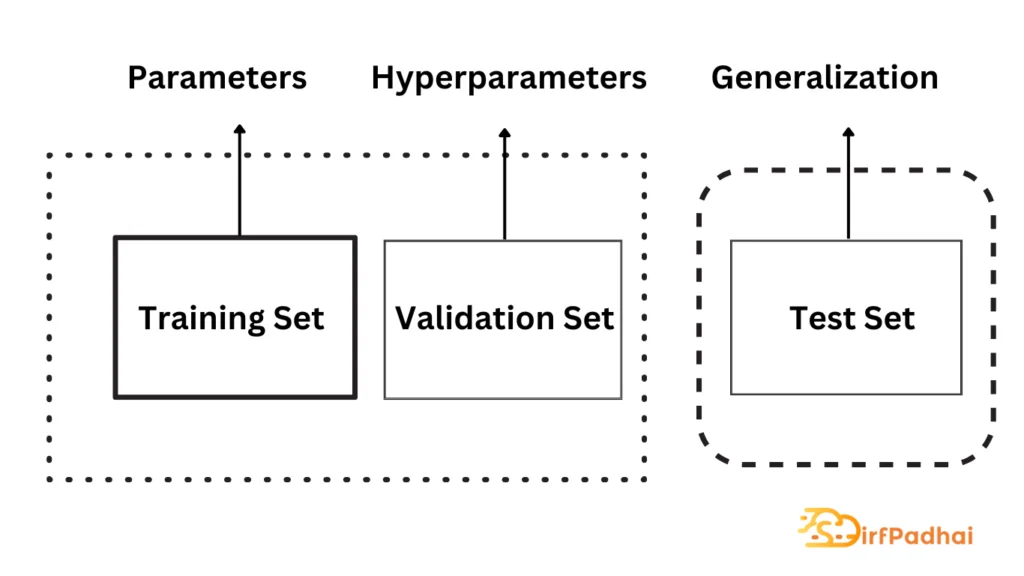
Fig. 2.15 Schematic Overview of Training, Validation, and Test Set
Training Set –
It is typically the largest of the three and is used to find the model parameters that best explain the underlying predictive relationship between the data and its labels. Most approaches that fit parameters based on empirical relationships with the training set alone tend to overfit the data, meaning that they can identify apparent relationships in the training data but, fail to do so in general. This motivates the use of a test set.
Test Set –
This is a set of data that is not used during training but follows the same probability distribution and predictive relationship. If a model performs well on the training set and also fits the test set well, i.e. predicts the correct label for a large number of unseen input data, minimal overfitting has taken place. It is important to note that the test set is usually only employed once as soon as the model’s parameters and hyperparameters are fully specified in order to assess the model’s generalization performance. However, to approximate a model’s predictive performance during training, a validation set is used.
Validation Set –
This is created by splitting the training set into two parts, the smaller of which is commonly used for hyperparameter optimization and to avoid overfitting through early stopping.
In order to choose favorable hyperparameters and maximize the model’s predictive performance, a validation set is used as an additional dataset for two reasons. If the training set were used to fit the hyperparameters and parameters simultaneously, the model tends to overfit the training set. On the contrary, if the hyperparameters were chosen with respect to the test set, the model implicitly fits the assumptions of the test data which would mitigate the unbiased assessment of its predictive performance and therefore its generality. These limitations sufficiently motivate the use of a third set for validation.
Early stopping is a universally applicable attempt to find the optimal time to stop the training process and to decide when a model is fully specified with respect to its parameters and hyperparameters. A common technique is to continuously monitor the so-called validation accuracy and to stop training when it stops improving. The validation accuracy can be seen as an approximation of the final classification performance that imposes minimal assumptions on the data’s predictive relationship, both theoretically and in practice.




")
