


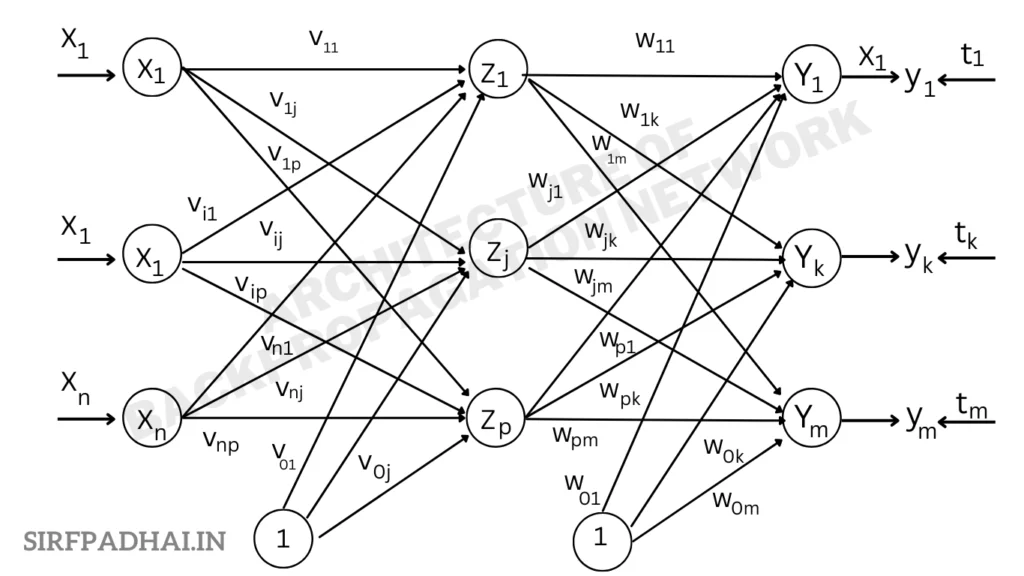
Architecture of backpropagation network
A back propagation neural network is a multilayer, feedforward neural network. It is made up of an input layer, a hidden layer, and an output layer. The neurons in the hidden and output layers contain biases. These biases are the connections from the units whose activation is always I. Also, the term bias works as weights. The architecture of a back propagation network illustrating only the direction of information flow for the feedforward phase is shown in Fig. 2.13. Signals are fed in the opposite direction during the backpropagation phase of learning. The inputs are sent to the BPN. The output achieved from the net could be either binary (0, 1) or bipolar (-1, +1).
The activation functions used in the backpropagation network are binary Sigmoidal and bipolar Sigmoidal activation functions.
These functions are used due to the following characteristics –
(i) Differentiability
(ii) Continuity
(iii) Nondecreasing monotony.
The binary Sigmoidal function range is between 0 to 1, and bipolar Sigmoidal function range is between -1 to +1.
How does backpropagation work?
The network learns a predefined set of input-output example pairs by using a two-phase propagate-adapt cycle. After an input pattern has been applied as a stimulus to the first layer of network units, it is propagated through each upper layer until the output is generated. This output pattern is then compared to the desired output, and an error signal is computed for each output unit. The error signals are then transmitted backward from the output layer to each node in the intermediate layer that contributes directly to the output. However, each unit in the intermediate layer receives only a portion of the total error signal, based roughly on the relative contribution the unit made to the original output. This process repeats, layer by layer until each node in the network has received an error signal that describes its relative contribution to the total error. Based on the error signal received, connection weights are then updated by each unit to cause the network to converge toward a state that allows all the training patterns to be encoded.
The significance of this process is that, as the network trains, the nodes in the intermediate layers organize themselves such that different nodes learn to recognize different features of the total input space. After training, when presented with an arbitrary input pattern that is noisy or incomplete, the units in the hidden layers of the network will respond with an active output if the new input contains a pattern that resembles the feature the individual units learned to recognize during training. Conversely, hidden-layer units have a tendency to inhibit their outputs if the input pattern does not contain the feature that they were trained to recognize.
As the signals propagate through the different layers in the network, the activity pattern present at each upper layer can be thought of as a pattern with features that can be recognized by units in the subsequent layer. The output pattern generated can be thought of as a feature map that provides an indication of the presence or absence of many different feature combinations at the input. The total effect of this behavior is that the BPN provides an effective means of allowing a computer system to examine data patterns that may be incomplete or noisy, and to recognize subtle patterns from the partial input.
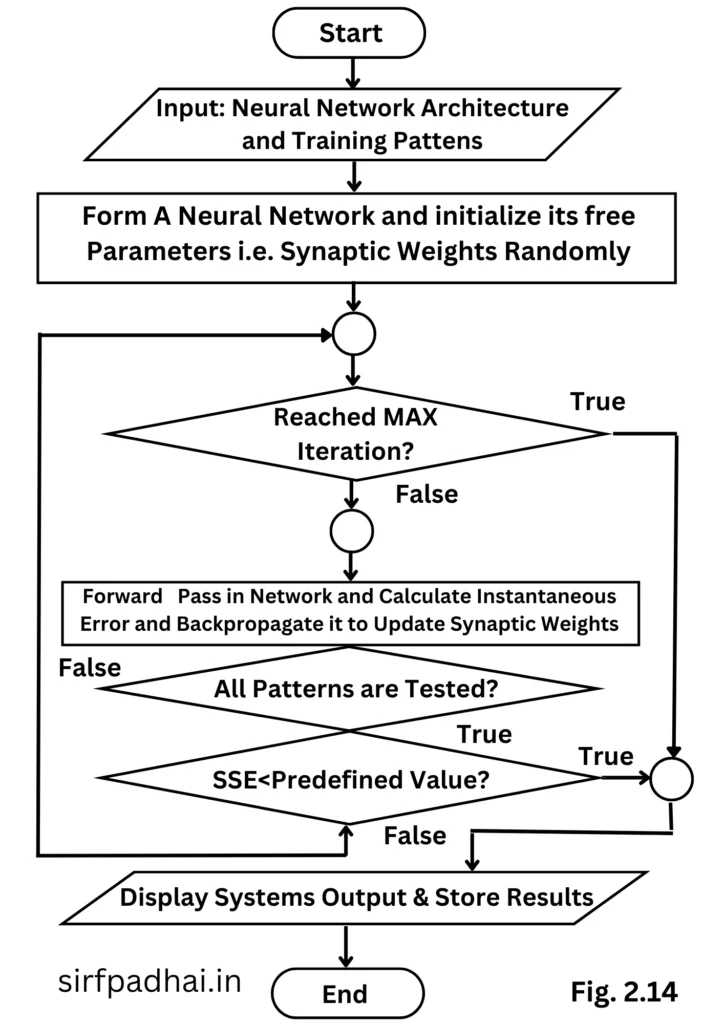
flowchart of backpropagation network




")
